



How Useful is Your Data?
This can probably be answered by assessing how much you can sort and filter the data. Data is essentially useless unless it is organised and accessible – (meaning filterable and sortable).
Data Granularity
Essentially granularity is a measure of the level of detail in a dataset.
A 2 column time-series dataset showing revenue by year can be considered low granularity – we have 5 rows of data.


This can be broken down and organised into nested sub-categories based on shorter intervals, such putting the same dataset into a table showing revenue by year, month, week, day, hour and even minutes.
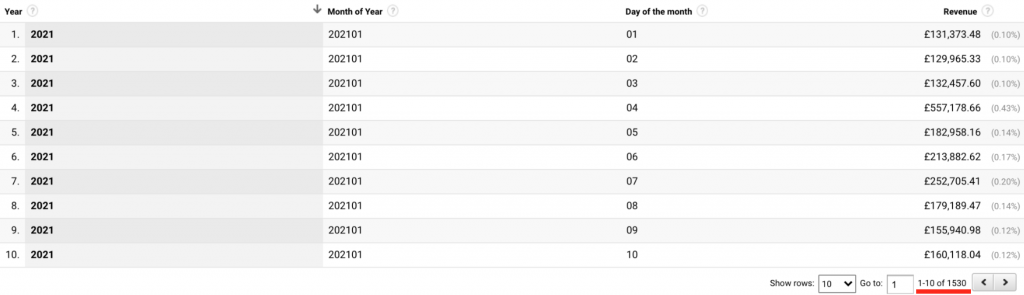

We now have more ‘granular’ or ‘high granularity’ data – the same dataset is now organised in to 1530 rows.
Having access to high levels of granularity let us aggregate and dis-aggregate data to spot trends on macro and micro scales. Maximum granularity (atomic) is ideal but expensive in terms of collection, processing and storing.
Low granularity offers less choices, or makes you use mathematical methods to get estimates of granularity which may be misleading.
For example, say Google Analytics shows a website gets 24 visits in 1 day. You could assume 1 visit per hour on average. Which is correct, but it might be no visits for 20 of those hours and then 4, 8, 8, 4 between 10am and 2pm. So you could miss vital insights.
Assessing what level of granularity you need to build into your tracking implementations should always be based on the maximum feasible in terms of ease to implement and cost, but other considerations such as reporting requirements and questions that you want answered should be taken into account.
If you only need to report on total per day or total per month = 1 day x 30.5 (average of a 12 month), then visits at day granularity is adequate.
However, if you need to know which hours of day are optimal for Facebook or Google Ads timed promotions, hour/minute granularity is useful. They can still be added together to get the daily if that is needed that too (lower granularity).
Hit level granularity in Google Analytics is great for statistical analysis and sub-segmentation based on technical or behavioural metrics.
However, there are added costs to setup collection, then methods are needed to get around sampling, then costs to store (warehouse) and process, cost to access/query that from the visualisation tool and these all add up. So the value you get from holding at the lowest possible granularity needs to be weighed against the cost of it.
Typically web statistics companies do what Google does, they hold atomic level millisecond transactional data in one big master collection database. They process that overnight or on a delay and expose only pre-aggregated values calculated from that master for users to access in reports, which is why the standard set of reports load at a reasonable sped in Google Analytics. As soon as you ask for something they haven’t already calculated, its either incredibly slow or they heavily sample it (increasing speed and reducing cost for them on a free tool), which is why Data Studio reports often take so long to load.
Data Cardinality
The term cardinality refers to the uniqueness of data values contained in a particular column (attribute) of a database.
Cardinality is how many differences there are / the number of elements; granularity is how many occurrences there are.
If you have 1000 unique SKUs per minute then you have high cardinality and high granularity. If you have 1 SKU 1000 times per minute then you have low cardinality (the lowest – 1) and high granularity.
When analysing data you might come across cardinality issues where the same element is being treated as unique due to formatting such as ‘shirts’ and ‘Shirts’ in a Search Terms report.
You would need to clean the dataset and aggregate these elements to make analysis possible. Of course a much better approach is ensuring that the data is collected in the correct format in the first place.
A similar issue can be seen in URL based reports such as the Landing Page report where technical URL parameters such as gclid (Google Ads click tracking parameter) or fbclid (the Facebook Ads equivalent) splinters out the same page into multiple rows.
Both cardinality and granularity affect the performance of querying speed. The higher the cardinality and/or granularity in a dataset the long it takes to query.